

PointNet is a deep learning network architecture proposed in 2016 by Stanford researchers and is the first neural network to handle directly 3D point clouds. In this article, I explain how PointNet works after reimplementing it with PyTorch. You can see the final result in the gif below:
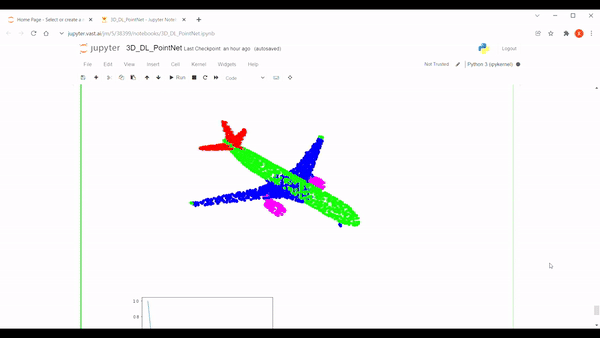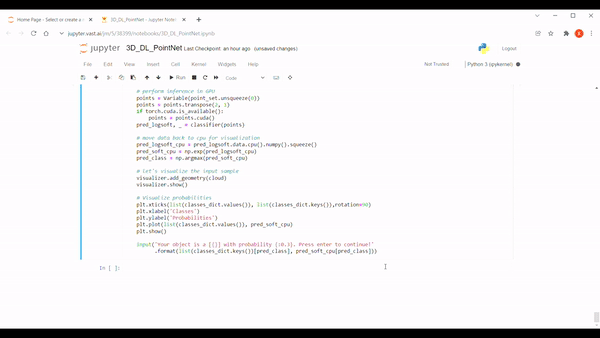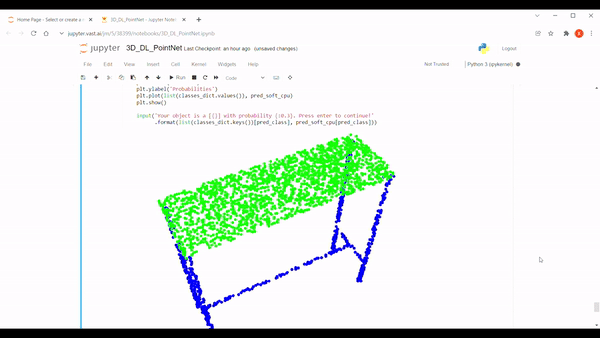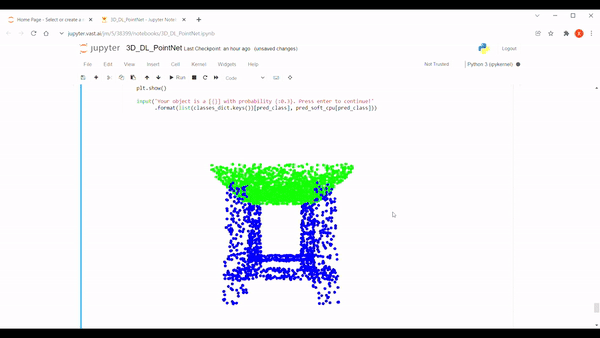
Like the original paper, we use the ShapeNet dataset for this project, which contains 16,881 shapes from 16 categories. After discussing briefly what a convolutional neural network is, we will explain the architecture of PointNet.
What is a Convolutional Neural Network
Convolutional networks are a type of neural network specifically designed to recognize patterns in data. They are called convolutional networks because they use convolutions to find patterns in data. Convolutional nets have been very successful in tasks such as recognizing faces, identifying objects in pictures, and classifying documents. This is because they can learn hierarchical representations of data that capture the essential structural features of the input data. In other words, a CNN is precisely engineered to be good at extracting meaningful information from images (or other types of data), such as the shapes of objects, their identities, their location within an image, etc. When we talk about convolution, it is the process of adding each element in an image to its local neighbors and weighted by a kernel, often a 3x3 matrix. The following gif illustrates this process in 2D.
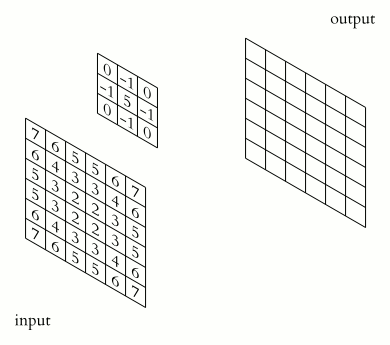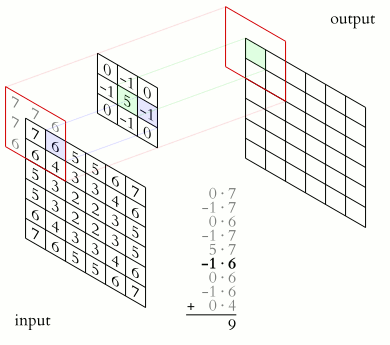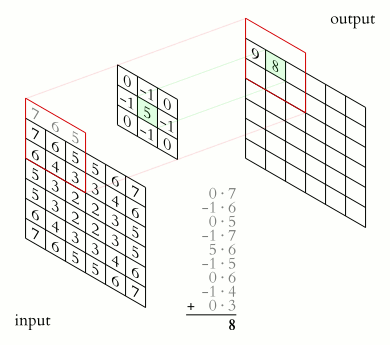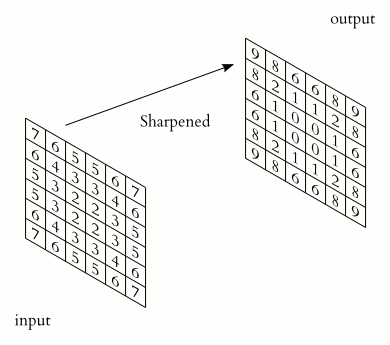
In 3D, the principle is the same, but instead of having computations between 2D matrices, the convolutions are done in 3D, between 3D matrices.
The Issues With Convolutional Neural Networks
While convolutional neural networks are powerful, they are also not very robust to rotations, translations, and scale changes.
This means that if an image is rotated, translated, or scaled differently than the training data, the network will not be able to identify it correctly.
This can be a problem because images can often be rotated, translated, and scaled in ways that are not detected during the training process. For example, an image of a cat that has been rotated by 90 degrees may not be correctly identified by a convolutional neural network as a cat.
One way of solving these issues is data augmentation, which can be done by adding rotated, translated images or by creating fresh new data with the help of a Generative Adversarial Network (GAN). In the case of PointNet, the solution uses a Spatial Transformer Network instead.
A spatial transformer network is a neural network architecture designed to put the input data in an ideal position in 3D space. This allows the network to more accurately represent complex data structures, such as point clouds, as they represent 3D structures.
With PointNet, we apply convolutions to a point cloud. However, we need to follow three rules when working with point clouds.
The Three Fundamental Rules When Working With Point Clouds
The issue when running convolutions on a point cloud is that the shape and the order of the point cloud are not taken into consideration.
A Point Cloud Must Be Invariant to N! Permutations
The data processing needs to be invariant to different permutated representations of the point cloud; this is due to the unstructured nature of the points in a point cloud.
Let’s say we have 5 points. And therefore, the number of possible permutations is 5! or 120. The fact that the point cloud must be invariant to permutations means that the order does not impact the result.
A Point Cloud Must Be Invariant to Rotations and Translations
Transformations like rotation and translation must not impact the classification and segmentation output. For example, if we rotate a cube, it’s still the same cube. Rotating an object does not impact the result.
A Point Cloud Must Be Sensitive to Local Structure and Geometry
The connections between neighboring points often carry useful information. It means that each point should not be treated in isolation. For example, a sphere is different from a pyramid. Neighboring points and geometrical structures must be considered.
It is important to note that these connections between points are more important for segmentation tasks than classifications.
Now, let’s explore the PointNet architecture.
Understanding PointNet Architecture
The diagram below shows the overall architecture of PointNet. PointNet is a model with two heads that can perform classification and segmentation.

Feel free to refer to the original paper for more information. In the following, we will explain how the input data is processed and passed into the classification and segmentation heads.
Data Transformation
A point cloud is a set of data points in space. In this case, each object in the dataset will be a set of data points.

In PointNet, the input is a number n of points multiplied by 3 (X, Y, Z) because we work in a 3D space with X, Y, Z coordinates.
The input needs to be invariant to rotations and translations, as we mentioned previously. This is achieved with the help of the T-Net network, which is a type of Spatial Transformer Network.
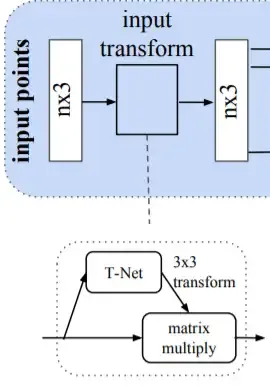
The purpose of T-Net is to align the input point cloud to a canonical representation.
The diagram below comes from this paper on Spatial Transformer Networks. This network aims to align the input data in an ideal space.
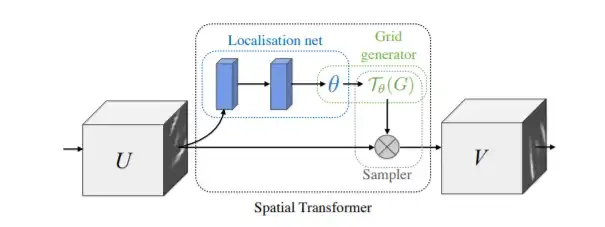
The spatial transformer network needs a localization network, a grid generator, and a sampler to achieve the result of aligning the input data in a canonical space.
The localization network can be any type of network as long as we have a regressor for θ.
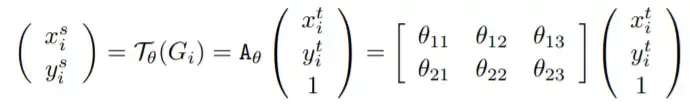
θ is a matrix of values that tells the input how much it needs to be rotated or change scale.
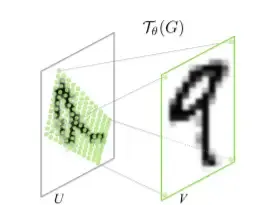
V is the target, and with the parameters θ, we try to find the source. In other words, we teach the network to retrieve the original point.
In this configuration, we are not trying to find the target, but instead, we try to find the source with the help of the target.
In the image above, V represents the target with the ideal configuration of the image. Because the input U is rotated, we want to determine how much we need to rotate the input to align it with the target.
And finally, to perform a spatial transformation of the input, a sampler takes the set of sampling points Tθ(G), along with the input U and creates the sampled output V.
The T-Net part of PointNet works similarly as its purpose is to align the input data in a canonical space (e.g., ideal space).
The T-Net makes the 3D input invariant to rotations and translations.
In the case of PointNet, we use a 1x1 convolution to achieve this step. The use of a convolutional neural network with 1x1 convolutions allows taking advantage of the weight-sharing features of CNNs while being faster by reducing the complexity of the model and retaining information.
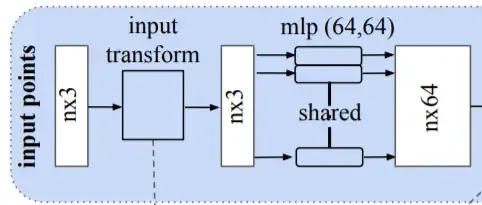
The output of the initial T-Net is still a point with 3 dimensions. The difference is that it has been rotated. Next, we want the input to be sensitive to local structure and geometry. For that, we send the input through a multi-layer perceptron (mlp) that will learn its structure and return an output in a higher-dimensional space of 64 dimensions.
For this, we use convolutions because, as mentioned previously, it has the property of sharing the weights.
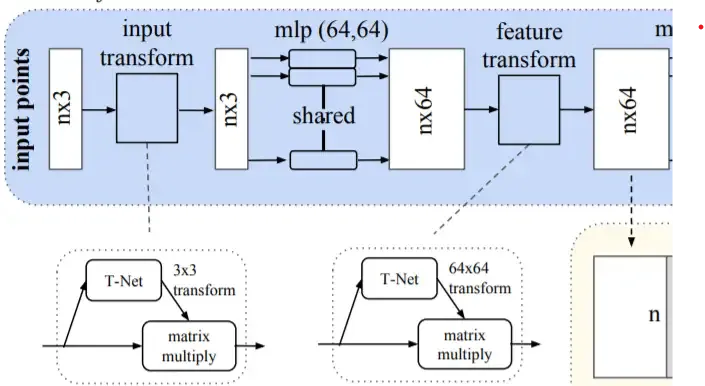
Next, this 64-dimensional input is sent to a feature transform step to align this feature representation to an ideal space. This step is performed with the help of another T-Net network; however, here, we have a 64x64 matrix instead of a 3x3.
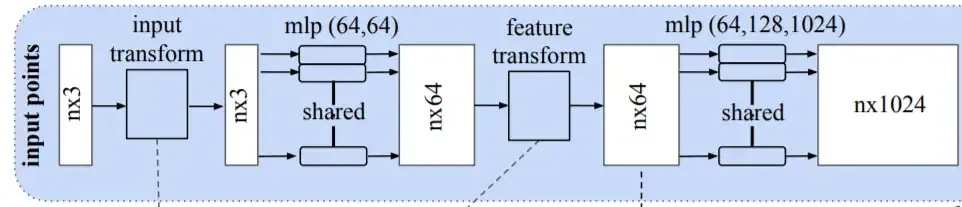
Then, we repeat the same process of having a multi-layer perceptron with convolutions where the input is mapped from 64 dimensions to 128, and finally 1024 dimensions. In other words, at the end of this process, a single data point carries 1024 pieces of information.

Next, we perform a max-pooling operation to reduce the number of dimensions and the noise. Because a max-pooling operation is invariant to the order, it is invariant to n! permutations. The information is stored in what is called a global feature vector.
PointNet Global Feature Vector
The picture below illustrates what information has been stored in the global feature vector.

PointNet Classification Head

Once we have our global feature vector, we can pass the data into the classification and segmentation heads. The classification head is more straightforward and is made of a three-layer-fully connected network to map the global feature vector to an output k, representing the number of classes we want to predict.
PointNet Segmentation Head
Regarding the segmentation network, each of the n inputs needs to be assigned to one of the m segmentation classes.
The segmentation process relies on local and global features. Therefore, the points with 64 dimensions representing the local features must be concatenated with the global features.
As a result, each point is classified in one of the segmentation classes, m. PointNet Architecture Overview With PyTorch If you build this model with PyTorch, below is the final architecture that you should get:
1class STN3d(nn.Module)2output:3stn torch.Size([32, 3, 3])4global feat torch.Size([32, 1024])5classification head:6global feat torch.Size([32, 1024])7point feat torch.Size([32, 1088, 2500])8class torch.Size([32, 5])9segmentation head:10PointNetDenseCls(11 (feat): PointNetfeat(12 (stn): STN3d(13 (conv1): Conv1d(3, 64, kernel_size=(1,), stride=(1,))14 (conv2): Conv1d(64, 128, kernel_size=(1,), stride=(1,))15 (conv3): Conv1d(128, 1024, kernel_size=(1,), stride=(1,))16 (mp1): MaxPool1d(kernel_size=2500, stride=2500, padding=0, dilation=1, ceil_mode=False)17 (fc1): Linear(in_features=1024, out_features=512, bias=True)18 (fc2): Linear(in_features=512, out_features=256, bias=True)19 (fc3): Linear(in_features=256, out_features=9, bias=True)20 (relu): ReLU()21 (bn1): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)22 (bn2): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)23 (bn3): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)24 (bn4): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)25 (bn5): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)26 )27 (conv1): Conv1d(3, 64, kernel_size=(1,), stride=(1,))28 (conv2): Conv1d(64, 128, kernel_size=(1,), stride=(1,))29 (conv3): Conv1d(128, 1024, kernel_size=(1,), stride=(1,))30 (bn1): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)31 (bn2): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)32 (bn3): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)33 (mp1): MaxPool1d(kernel_size=2500, stride=2500, padding=0, dilation=1, ceil_mode=False)34 )35 (conv1): Conv1d(1088, 512, kernel_size=(1,), stride=(1,))36 (conv2): Conv1d(512, 256, kernel_size=(1,), stride=(1,))37 (conv3): Conv1d(256, 128, kernel_size=(1,), stride=(1,))38 (conv4): Conv1d(128, 3, kernel_size=(1,), stride=(1,))39 (bn1): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)40 (bn2): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)41 (bn3): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)42)43seg torch.Size([32, 2500, 3])
Finally, if you haven’t yet, you can watch the results in the video below:
You can also watch the entire video on Youtube here.
Closing Thoughts
Because PointNet was a pioneering network in handling directly 3D data) points from point clouds, it is important to understand well how it works. After understanding the underlying principles of working with point clouds data, we explained how the input is processed before being passed into the classification and the segmentation head. This project has been built using the Spatial Transformer Networks and PointNet papers, as well as resources from ThinkAutonomous.ai.

